Amazon S3
Amazon Simple Storage Service(Amazon S3)は、シンプルなストレージを提供するAWSリソース。他のAWSリソースと連携して、データを保存する役割を担うよ。
Amazon S3は、文字、写真、動画など様々なデータ(オブジェクト)を、バケットの中に入れて保存する。最終更新日やサイズなど、オブジェクトを管理するための情報をメタデータというよ。
Amazon S3は、イレブンナイン(99.999999999%)と呼ばれる高い耐久性を持つ。Amazon S3に1万個のデータを保存している場合、そのうち1つのデータが失われることは、1千万年に1度しか起こらない。一生の中で、Amazon S3内のデータ損失に立ち会う確率はかなり低いといえる。
また、Amazon S3に保存されたデータは、自動的に3つのアベイラビリティゾーンに保存される。3つのアベイラビリティゾーン間で、データの整合性が保たれているため、1つのアベイラビリティゾーンに障害があっても、残り2つのアベイラビリティゾーンで稼働を続けることができるよ。
これらの特徴から、Amazon S3にデータを保存すること自体がバックアップを取るようなものといえる。Amazon S3にデータを保存するだけで、バックアップ、故障、火災、水災、地震といった心配から解放される。Amazon S3に入れたデータは、ほぼなくなることがないよ。
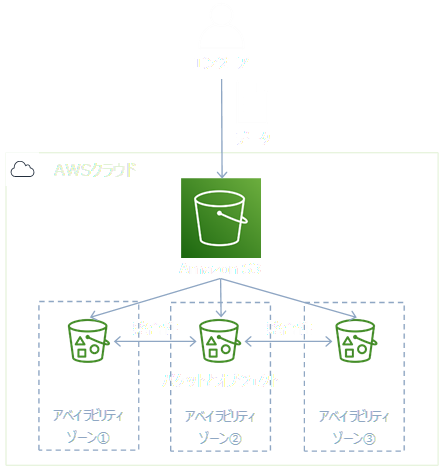
1つのデータは、5KBまでオブジェクトとして保存できる。バケットの中に入れられるオブジェクトの数は無制限だよ。
オブジェクトは、リクエストを送ることで操作する。具体的には、GETで取得、LISTで参照、PUTで作成、DELETEで削除するよ。
Amazon S3の整合性は強い一貫性。リクエストはすぐに反映され、常に最新の状態に保たれている。
ストレージタイプ
Amazon S3は、保存したデータの量や期間、リクエストに対して課金される。もともと非常に安いのだけど、適切なストレージタイプを選ぶことによって、さらにコストを抑えることができる。
Amazon S3のストレージタイプは、STANDARD、STANDARD-IA、One Zone-IA、RRS(Reduced Redundancy Storage)、Amazon Glacier、Amazon Glacier Deep Archive、S3 Intelligent-Tieringの7つがある。
| タイプ | STANDARD | STANDARD -IA |
One Zone -IA |
RRS | Amazon Glacier |
Amazon Glacier Deep Archive |
S3 Intelligent- Tiering |
|---|---|---|---|---|---|---|---|
| 特徴 | よくアクセスされるデータを保存 | 少しアクセスされるデータを保存 | 少しアクセスされるデータを保存 | 非推奨 | ほぼアクセスがないデータを保存 | ほぼアクセスがないデータを保存 | アクセス頻度が不明データを保存 |
| 取出しに掛かる時間 | すぐにデータを取出すことができる | すぐにデータを取出すことができる | すぐにデータを取出すことができる | すぐにデータを取出すことができる | 取り出しオプションによって異なる(数分~数十時間) | 取り出しオプションによって異なる(数分~数十時間) | すぐにデータを取出すことができる |
| コスト | 高い | STANDARDよりやや安い | STANDARDより安い | STANDARDより高い | 安い | Amazon Glacierより安い |
階層によって異なる |
| 耐久性 | 99.999999999% | 99.999999999% | 99.999999999% | 99.99% | 99.999999999% | 99.999999999% | 99.999999999% |
| 可用性 | 99.99% | 99.9% | 99.5% | 99.99% | 99.9% | 99.99% | 99.9% |
| 保存 方法 | 3つ以上のアベイラビリティゾーンに保存 | 3つ以上のアベイラビリティゾーンに保存 | 1つのアベイラビリティゾーンに保存 | 3つ以上のアベイラビリティゾーンに保存 | 3つ以上のアベイラビリティゾーンに保存 | 3つ以上のアベイラビリティゾーンに保存 | 3つ以上のアベイラビリティゾーンに保存 |
| 最低 期間 |
なし | 30日間 | 30日間 | なし | 90日間 | 180日間 | 30日間 |
STANDARDやSTANDARD-IAは、パフォーマンスとコストのバランスが良く、一般的な用途に適している。アクセスが多いならSTANDARD、アクセスが少ないならSTANDARD-IAに保存するよ。
One Zone-IAは、1つのアベイラビリティゾーンでしかデータが保存されない。アクセスが少なく、消失しても大きな問題にならないデータを保存することに適している。コスト削減を図りつつ、ログを保存するような用途に最適。
RRSは、料金が高いうえに耐久性が低いため非推奨。RRSではなく、STANDARDを使うことが推奨されるよ。
Amazon Glacierは、バックアップやアーカイブに適している。かなりコストを削減できるけど、保存したデータの取出しに時間が掛かるのが難点。データの取り出し方は、標準取出し、一括取得、迅速取出しの3つがある。標準取出しは12時間以内、一括取得は48時間以内、迅速取出しは1~5分でデータを取り出せる。日常的に使用することはなくても、最低5年間は残しておかなければならない顧客情報などの保存に最適。
Amazon Glacier Deep Archiveは、Amazon Glacierと同じ役割や特徴を持つ。Amazon Glacierより安くデータを保存できるけど、データの取出しに最低でも数時間掛かる。データの取り出し方は、標準取出し、大量取出しの2つがある。標準取出しは3~5時間、大量取出しは5~12時間でデータを取り出せる。
S3 Intelligent-Tieringは、アクセス頻度に応じて自動的に階層を移動することにより、コスト最適化を図る。オブジェクトのアクセス頻度が不明または予測できない場合に適しているよ。
最低期間は、実際の使用の有無に関わらず、使ったとみなす期間のこと。例えば、STANDARD-IAに15日間データを保存した場合30日分、45日間データを保存した場合45日分の請求が来るよ。
ライフサイクル
ライフサイクルは、一定期間後にストレージタイプを変更、またはオブジェクトを削除する機能。
アクセスが多い最初の30日間はSTANDARDに入れて、その後は保管のためにAmazon Glacier Deep Archiveに移すといった設定が可能。また、30日後に削除する設定にすることもできるよ。
S3 Intelligent-Tiering
以前は、エンジニアがオブジェクトのアクセス頻度を分析して、費用対効果の高いストレージクラスを選び、ライフサイクルで移動させていた。アクセス頻度の分析は、非常に時間と手間が掛かり、正確に予測できない場合もあった。
しかし、S3 Intelligent-Tieringによって、オブジェクトのアクセス頻度の分析や予測の必要がなくなった。S3 Intelligent-Tieringに保存するだけで、自動的にコストとパフォーマンスが最適化される。
S3 Intelligent-Tieringは、高頻度のアクセス層、低頻度のアクセス層、アーカイブアクセス層、ディープアーカイブアクセス層の4つの階層で構成されている。
高頻度のアクセス層はSTANDARD、低頻度のアクセス層はSTANDARD-IA、アーカイブアクセス層はAmazon Glacier、ディープアーカイブアクセス層はAmazon Glacier Deep Archiveと性能とコストが同じだよ。
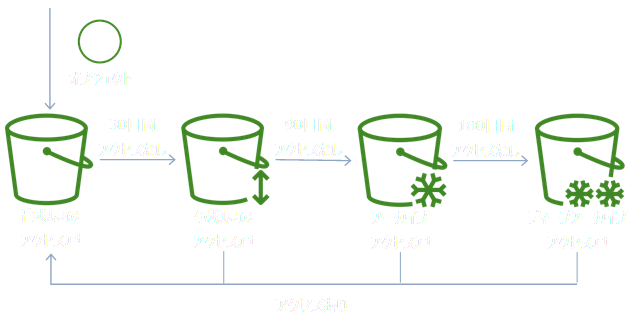
高頻度のアクセス層にあるオブジェクトが30日アクセスされないと、そのオブジェクトは自動的に低頻度のアクセス層へ移動する。同じように、低頻度のアクセス層で90日アクセスされないとアーカイブアクセス層へ、アーカイブアクセス層で180日アクセスされないとディープアーカイブアクセス層へオブジェクトを自動的に移動する。
その後、アクセスされると、オブジェクトは高頻度のアクセス層に自動で戻る。アクセス頻度に応じて4つの階層を移動することにより、ほぼアクセスされないオブジェクトのコストを最大95%削減できるよ。
セキュリティ
アクセス管理と暗号化で、Amazon S3のセキュリティを高めることができるよ。
アクセス管理
アクセス管理によって、誰が何に対してアクセスできる、またはできないといった制限をすることが可能だよ。
Amazon S3のアクセス管理は、IAMポリシー、ACL(Access Control List)、バケットポリシーで行う。
IAMポリシーはユーザー単位で、ACLとバケットポリシーはバケットまたはオブジェクト単位でアクセス権限を制御する。
ACLとバケットポリシーに大きな差はないけど、バケットポリシーの方が細かい設定ができるよ。
- バケットポリシー
バケットポリシーは、JSON形式で定義する。バケットポリシーの例はこちら。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "IPAllow", "Effect": "Deny", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::awsbucket" ], "Condition": { "NotIpAddress": {"aws:SourceIp": "54.240.143.0/24"} } } ] }VersionとSidには、バケットポリシーの名前を書く。
Sidの方がVersionより詳細な名前になる。
Effectは、許可か拒否かを分けるところで、Allowなら許可、Denyなら拒否をする。
Principalには、アクセスを許可または拒否するユーザーやAWSアカウントを記述する。今回は*と書かれているので、全てという意味になる。
Actionには、どのような行為かを書く。s3:*は、PUTやDELETEなど全てのリクエストという意味。
Resourceには、何に対してかを書く。今回は、awsbucketというバケット名が書かれている。
Conditionには、条件を書く。NotIpAddressは、指定のIPアドレス以外という意味。
このバケットポリシーが適用されている場合、54.240.143.0/24の範囲内のIPアドレス以外、awsbucketに対して、全ての操作を行うことができない。
- 署名付きURL
署名付きURLは、期限付きのURLを渡すことでアクセスを許可するもの。一時的にアクセス権限を与えたい場合に適している。
方法は簡単で、アクセスを許可したい人にURLを渡す。そして、そのURLからオブジェクトにアクセスしてもらう。 URLの期限が切れると、URLからオブジェクトにアクセスできなくなる仕組みだよ。
署名付きURLは、セキュリティの観点から見たとき、一時的なアクセス権限を与えることができる点が良いといえる。
しかし、URLを知っていれば誰でもアクセスできてしまうことが欠点。URLが流れてしまえば、どんな人でも期限が切れるまでアクセスできてしまうので、その点だけは注意するべきだよ。
- パブリックアクセス
パブリックアクセスは、バケットやオブジェクトに対して、インターネットとの通信の可否を設定するもの。
パブリックアクセスを有効にすると、インターネットと通信できるようになる。パブリックアクセス無効時は、インターネットとの通信することができない
セキュリティが重視される場合は、パブリックアクセスを無効にすることが望ましいよ。
暗号化
オブジェクトを暗号化することで、更にセキュリティを高めることができるよ。
- サーバーサイド暗号化とクライアントサイド暗号化
オブジェクトを暗号化する方法は、サーバーサイド暗号化とクライアントサイド暗号化がある。サーバーサイド暗号化は、Server Side Encryptionを略してSSEと表記される。クライアントからデータが送られてきた時にサーバー側で暗号化し、クライアントへデータを渡す前にサーバー側で複合を行う。
また、クライアントサイド暗号化は、Client Side Encryptionを略してCSEと表記される。データをクライアント側で暗号化してからサーバーに送り、サーバーから受け取った後にクライアント側で復号する。
まとめると、サーバーサイド暗号化とクライアントサイド暗号化は、暗号化と複合が行われる場所とタイミングが異ななるよ。


クライアントは、サーバーからデータを受け取る側のこと。それはソフトウェアを指すことがあり、エンジニアを指すこともあり、広い意味合いで使われる言葉だよ。
- SSE-S3、SSE-KMS、SSE-C、CSE-KMS、CSE-C
オブジェクトを暗号化する方法には、サーバーサイド暗号化に当たるSSE-S3、SSE-KMS、SSE-Cと、クライアントサイド暗号化に当たるCSE-KMS、CSE-Cに分かれる。
鍵の管理の手間を省きたいならSSE-S3、AWS KMSを使いたいならSSE-KMSかCSE-KMS、自前の鍵を使いたいならSSE-CかCSE-Cといったように、要件に合わせて選ぶことができるよ。暗号化と複合の方法 鍵管理 SSE-S3 Amazon S3のキーを用いて、サーバー側で行われる AWSが管理 SSE-KMS AWS KMSのキーを用いて、サーバー側で行われる AWSとエンジニアが管理 SSE-C エンジニアが準備したキーを用いて、サーバー側で行われる エンジニアが管理 CSE-KMS AWS KMSのキーを用いて、クライアント側で行う AWSとエンジニアが管理 CSE-C エンジニアが準備したキーを用いて、クライアント側で行う エンジニアが管理 SSE-KMSとCSE-KMS は、AWS KMSの追加料金が発生するよ。
応用
Amazon S3には豊富な機能があり、それらによって他の機能やAWSリソースと柔軟に連携することができるよ。
- S3イベント
S3イベントは、Amazon S3の処理をトリガーに、他のAWSリソースを起動するもの。オブジェクトの作成や削除を引き金に、AWS Lambda 、Amazon SQS 、Amazon SNSなどと連携できる。
例えば、Amazon S3に画像が保存された際、AWS Lambdaで画像加工するといった処理が可能だよ。- バージョニングとMFA Delete
Amazon S3に保存したデータほぼ無くならないけど、悲しくもエンジニアが誤ってデータを消してしまう可能性は残る。
手作業による誤操作でデータが損失することを防ぐためには、バージョニングとMFA Deleteが役に立つよ。
バージョニングは、オブジェクトのバージョン管理をするもの。バージョニングを有効化しておけば、誤操作より前の状態に戻すことができる。
MFA Deleteは、オブジェクトを削除時などに認証を挟む機能。MFA Deleteを有効化しておけば、上書きや削除の前に認証を行うことができるよ。- ボールドロック
ボールドロックは、オブジェクトを保護する機能。一定期間または無期限に、上書きや削除をできなくする。
金融業界など要件が厳しい場合、上書きや削除が不可能な状態でデータを保存するよう定められていることがある。また、外部に委託する際など、絶対に消してほしくないデータを渡さなければならないような状況もあるよ。
そういった場合に、上書きや削除の対策をするのではなく、上書きや削除ができないように設定するものがボールドロック。
オブジェクトを保護する方法には、コンプライアンスモードとガバナンスモードの2つがある。ガバナンスモードより、コンプライアンスモードの方がオブジェクトを厳しく保護する。
コンプライアンスモードは、例えルートユーザーであっても、期限内に解除することはできない。
ガバナンスモードは、AWS IAMで解除の権限を持っていれば、期限内でも解除することができるよ。- Amazon S3 Access Points
Amazon S3 Access Pointsは、アクセスポイントによってアクセス管理をするもの。
バケットポリシーなどJSON形式でアクセス管理をしても良いけれど、アクセス元が増えるとコードが長くなってしまう。
コードが数千行に及ぶのでは、どのようなアクセス管理がされているのかを理解することが困難になる。コードの見通しが悪くなるような場合、Amazon S3 Access Pointsを使うことで、視覚的に分かりやすくアクセス管理をすることができるよ。- Access Analyzer for S3
Access Analyzer for S3は、不要に外部に公開されているバケットを検出して、すぐに遮断することができるもの。
例えば、意図せずにパブリックアクセスを有効にしてしまったバケットがあるとする。それを検出すると、Access Analyzer for S3はバケットがパブリックアクセスを有効にしていて良いのかという警告を出す。
これにより、エンジニアは不要な公開にすぐ気づくことができ、数回のクリックでパブリックアクセスを無効にすることができるよ。
Access Analyzer for S3の導入は短時間で行うことができ、追加料金もかからないので、アクセス管理の良きサポートになると思うよ。- クロスリージョンレプリケーション
クロスリージョンレプリケーションは、オブジェクトを別リージョンに複製する機能のこと。バージョニングに付随した機能なので、バージョニングを有効にするとクロスリージョンレプリケーションができるようになる。
Amazon S3は、耐久性が99.999999999%だけど、可用性は99.99%だよ。デフォルトで地理的に離れた複数のアベイラビリティゾーンにデータを保存するけど、可用性の要件が厳しいと更に距離を離さなければならない場合がある。
そこで、クロスリージョンレプリケーションを使えば、かなり離れたリージョンに複製することができ、厳しい要件を満たすことができる。また、ユーザーとの距離を縮めることにも繋がるので、レイテンシーを低く抑えることもできるよ。- Amazon S3 Transfer Acceleration
Amazon S3 Transfer Accelerationは、長距離の転送を高速に行うもの。
グローバル展開しているアプリでは、ユーザーがどの位置にいても安定して高速にデータを転送できることが求められる。そういった場合、Amazon S3 Transfer Accelerationを用いれば、それを実現することができるよ。
Amazon S3 Transfer Accelerationは、エッジロケーションを活用して最適な経路を通ることにより、長距離のデータ転送を高速化するよ。- 静的Webサイトホスティング
ITの分野では、変わらないことを静的と表現する。画像や文字など、いつアクセスしても変わらないものは静的なコンテンツだよ。
それに対して、変わるものは動的と表現する。掲示板などアクセスするタイミングによって内容が変わるものは動的なコンテンツにだよ。
静的WEBサイトホスティングは、静的なWebサイトを公開するもの。動的なWebサイトを公開したい場合、静的Webサイトホスティングでは取り扱えないので、EC2インスタンスで公開することになる。
しかし、簡単なホームページであれば、EC2インスタンスで公開するより、静的Webサイトホスティングの方が安く済ませることができる。静的なWedサイトを公開する際は、このやり方がお勧め。- CORS
通常、ユーザーがブラウザから1つのページを見るためにアクセスするドメインは1つ。
ただ、クロスドメインというもので、2つのドメインを使用する場合もある。 例えば、商品紹介ページまではドメインが「aaa.example.com」で、買い物かごページからはドメインが「bbb.example.com」になるといったもの。
ドメインを分ける1つの理由としては、ユーザーがどのページを閲覧した後に買い物かごページに遷移したのか、後から分析するため。しかし、クロスドメインはクロスサイトスクリプティングに使われる危険性がある。安全なページ内にある普通の広告を押しただけで、「ccc.example.com」という悪質なページに飛ばされてしまうのでは、ユーザーは安心して使用することができない。
そういったセキュリティ上の懸念から、1つのページに結び付けるのは1つのドメインにするべきとされ、クロスドメインはできないように制限されていることが多い。どうしてもクロスドメインを実装したい場合、抜け道を見つけるように無理して作っていた。
CORS(Cross-Origin Resource Sharing)は、安全に複数のドメインと通信するための仕組み。複数のドメインと通信するルールを設定することによって、クロスドメインで抱えていたセキュリティ上の課題を解決するよ。
主な使い道としては、Amazon CloudFrontから静的なコンテンツを読み込んで、Amazon S3から動的なコンテンツを読み込むことが挙げられる。- マルチパートアップロード
マルチパートアップロードは、大きなデータを複数のパートに分割して、高速にAmazon S3にアップロードするもの。やり方としては、大きな家具を組み立てた状態で送るのではなく、分かれた状態で送って到着後に組み立ててもらうようなもの。
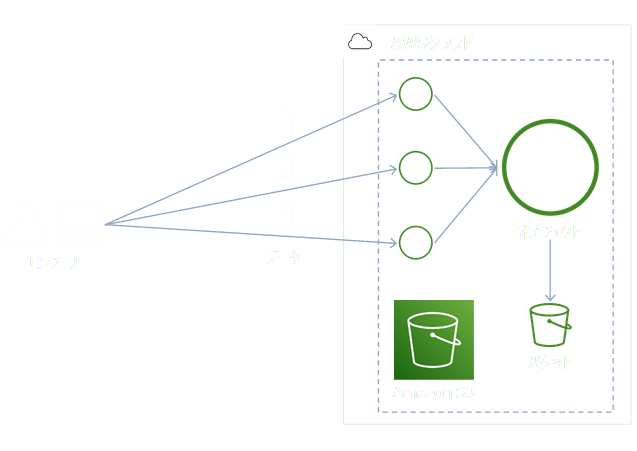
マルチパートアップロードは、100MB以上のデータをアップロードする際に使うことが推奨されている。そのくらいデータが大きくなると、アップロードに時間が掛かってしまうため。
1回のPUTで5GBまでアップロードできるので、各パートは5MB~5GBになるよう分割する。最後のパートのみ、5MB~5GBの範囲内に収まらなくても大丈夫。5GB、5GB、3MBの3つのパートにすれば、10GBと3MB分のデータをアップロードすることができる。
もし、アップロード中に何らかのトラブルで中断してしまった場合、途中から再開することもできる。複数のパートに分割してアップロードされたデータは、最後にAmazon S3で合成されるよ。- Amazon S3 Batch Operations
Amazon S3 Batch Operationsは、オブジェクトに対してバッチ処理を行えるもの。
大規模なシステムになると、オブジェクト数が億単位になる場合がある。仮に、数十億個のオブジェクトのコピーをそれぞれ作成するとなると、多くの時間と人を割かなくてはならない。
そこで、Amazon S3 Batch Operationsを使えば、大量のオブジェクトに対してコピーを作成することや、バッチ処理が行える。大幅に作業量を減らすことができるので、オブジェクト数が多い場合に必須の機能になるよ。
データの分析
Amazon S3に保存されたデータは、後に分析することができる。Amazon S3は、大量のデータを安く保存し、他のAWSリソースと連携して分析することができるので、ビックデータの用途で活躍する。
Amazon S3に保存されたデータを分析する方法は、S3 Select(Glacier Select)、Amazon Athena、Amazon Redshift Spectrumの3つ。
S3 Selectは、SQLを使って集計や検索ができるもの。特に、Amazon GlacierにSQLを使う機能をGlacier Selectという。Amazon Glacier からデータを取り出す際、取出しオプションよっては長時間掛かるけれど、Glacier Selectなら短時間でデータを取り出すことができる。
Amazon Athenaは、S3 Select(Glacier Select)と同じく、SQLを使って集計や検索ができるもの。S3 Select(Glacier Select)より、Amazon Athenaの方が複雑な分析ができる。
簡単な分析にはS3 Select、腰を据えて分析するにはAthenaが適しているよ。
Amazon Redshift Spectrumは、データレイクの分析に使われるもの。データレイクは、ビックデータを入れるデータベースのこと。大きなデータの分析には、Amazon Redshift Spectrumが適しているよ。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "IPAllow",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::awsbucket"
],
"Condition": {
"NotIpAddress": {"aws:SourceIp": "54.240.143.0/24"}
}
}
]
}